国产大模型调用量首次反超,OpenAI该慌了吗?
阿里、字节、谷歌同日"亮剑",AI竞赛从参数转向落地
2026年的大模型发布会,就像早高峰的地铁——你刚挤上去,下一班又来了。
一起来看下今天的热点新闻~
01|阿里千问3.6-Plus:国产编程能力最强模型来了
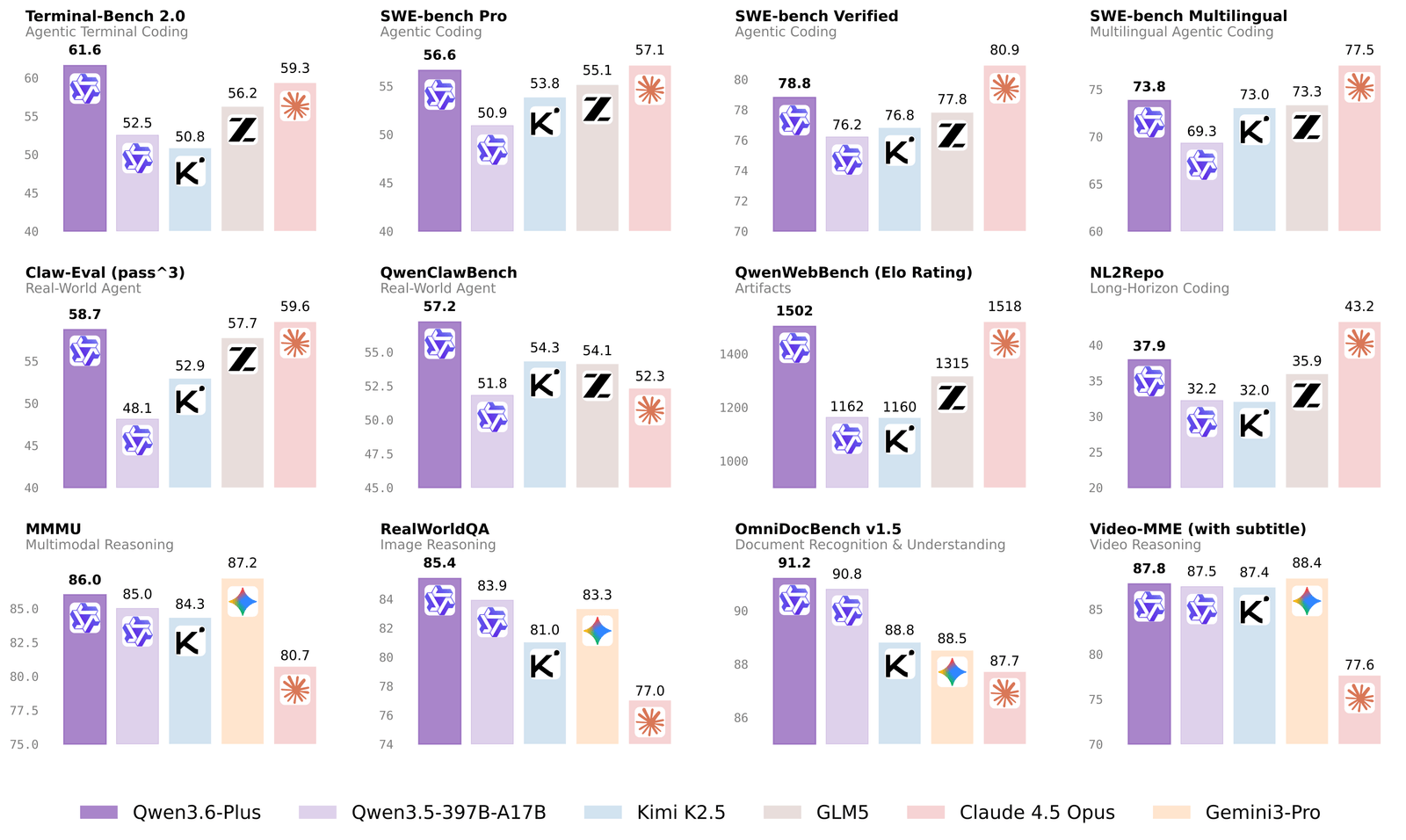
2026年4月2日,阿里云发布Qwen3.6-Plus,官方直接打出"中国编程能力最强模型"的旗号。
这不是营销话术。
Qwen3.6-Plus在多项编程能力测试中拿到领先成绩。它能拆解复杂代码任务,规划执行路径,测试、修正,一直到最后。
三个核心能力:
- 代理式编程(Agentic Coding):AI不再只写代码片段,而是独立完成整个开发流程。
- 原生多模态推理:看懂界面截图、设计稿,直接生成代码或修改界面。
- 100万token长上下文:一次能记住超长文档、复杂代码库,不用反复喂信息。
💡 Token是AI理解文本的基本单位,类似字数。100万token相当于一部长篇小说的量级。
定价对比一下:
- Qwen3.6-Plus:2元/百万token
- GPT-4o:约75元/百万token
- Claude 3.5 Sonnet:约105元/百万token
几乎是成本价。
模型已上架阿里云百炼平台,支持OpenAI和Anthropic的API接口规范,开发者迁移成本几乎为零。
📌 对你意味着什么:如果你在做代码生成、智能体开发,国产模型的能力已经足够硬核,成本优势明显。是时候认真考虑技术选型了。
02|豆包大模型:一天消耗120万亿Token,这是什么概念?
字节跳动旗下的火山引擎公布了一个数据:豆包大模型日均Token使用量突破120万亿。
三个月前,这个数字是60万亿。两年前,还不到1万亿。
增长1000倍,只用了24个月。
120万亿Token是什么量级?
对比一下全球其他AI平台:
| 平台 | 日均Token消耗 | 备注 |
|---|---|---|
| 豆包 | 120万亿 | 2026年4月数据 |
| Google Gemini | 43万亿 | 2025年10月数据 |
| OpenAI API | 8.64万亿 | 不含ChatGPT订阅用户 |
| 微软 | 1.7万亿 | 2025财年Q3峰值 |
豆包的消耗量,已经是OpenAI的近14倍。
为什么这么高?
- AI视频生成爆发:生成15秒视频消耗约30.9万Token。一部AI漫剧能烧掉上亿Token。
- 智能体普及:智能体不是简单对话,是任务拆解、工具调用、结果校验的多轮操作,Token消耗成倍增长。
- 企业场景加速落地:工作流嵌入、业务自动化,都在推高Token需求。
中国大模型的周调用量,已连续三周超越美国。
这不是"我们也能做",是"我们做得更大"。
📌 对你意味着什么:Token消耗背后是真实业务量。如果你在考虑大模型应用,国内平台的承载能力、成本优势正在快速拉开差距。
03|谷歌Gemma 4:31B参数打败400B模型,凌晨突袭开源
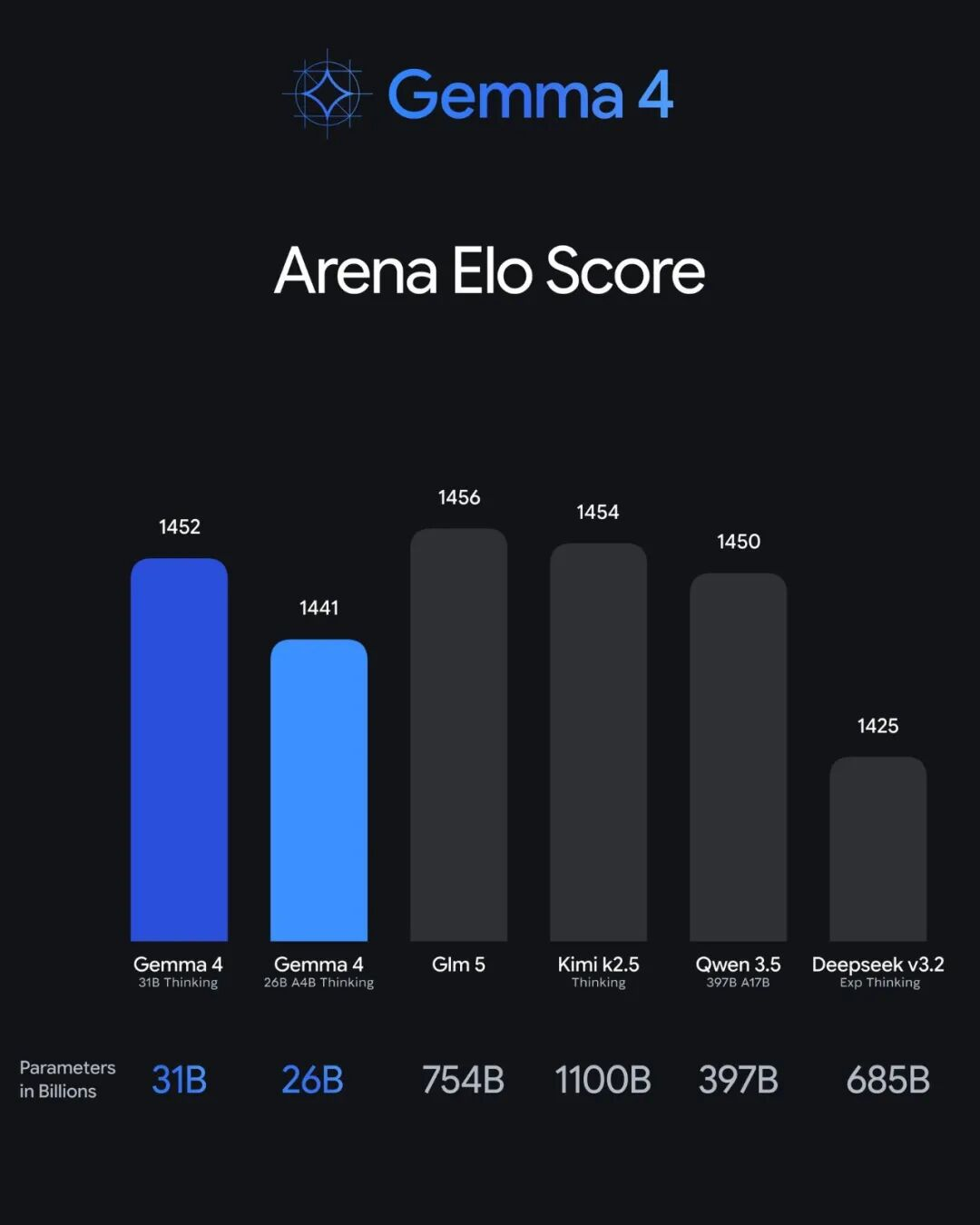
北京时间4月3日凌晨,谷歌DeepMind CEO Demis Hassabis发了一条推文:四个钻石表情符号。
随后,Gemma 4正式发布。
这次最大的变化不是性能,是协议——谷歌彻底放弃了Gemma 3的自定义协议,改用Apache 2.0,完全开源,商业可用,无限制修改。
四个版本,覆盖全场景:
| 模型 | 参数量 | 特点 |
|---|---|---|
| E2B | 20亿 | 手机端离线运行,原生支持音频 |
| E4B | 40亿 | 边缘设备优化,低延迟 |
| 26B-A4B (MoE) | 260亿(激活38亿) | 混合专家架构,推理速度快 |
| 31B Dense | 310亿 | 极致质量,长上下文25.6万token |
💡 MoE(混合专家架构)就像一个100人的团队,每次只叫其中6个人开会,成本低、速度快。
性能有多强?
用31B参数,打出了400B级模型的表现:
- MMLU Pro:85.2%(综合知识理解)
- AIME 2026数学竞赛:89.2%(Gemma 3只有20.8%)
- LiveCodeBench v6代码生成:80.0%
- Codeforces ELO:2150分(编程竞赛级)
全系原生支持140+语言,包括中文。
模型已在Google AI Studio、Hugging Face、Kaggle等平台开放下载。
📌 对你意味着什么:如果你需要部署端侧AI(手机、边缘设备),或者需要完全开源可商用的模型,Gemma 4值得认真研究。31B参数在消费级显卡上就能跑。
04|国家药监局:AI正式纳入药品监管体系
4月2日,国家药监局发布《关于"人工智能+药品监管"的实施意见》。
这是首次将AI正式纳入药品监管体系。
两个时间节点:
- 2030年:初步构建药品监管与人工智能融合创新体系,建成高质量数据集、垂直大模型和智能体。
- 2035年:基本形成数智驱动、智能敏捷、自主可控的智慧化药品安全治理新格局。
七大应用场景:
- 智能审评审批:推动"两品一械"审评审批大模型研发。
- 全链条监管:从研制、生产到流通使用,全覆盖数智化。
- 风险监控:高风险品种(疫苗、血液制品)智能监控。
- 检查执法:移动执法、"扫码入企"。
- 协同监管:跨区域、跨部门智能分派。
- 政务服务:智能问答、智能预填。
- 产业协同:制定AI在医药产业应用的指导原则。
这意味着什么?
AI不再是锦上添花,是监管现代化的基础设施工具。
📌 对你意味着什么:如果你在医药行业,AI合规应用将迎来明确政策指引。监管层已在推动,企业需要跟上节奏。
05|新华社定调:2026年是智能体爆发年
《环球》杂志4月2日发布深度报道,标题直白:2026:智能体爆发年。
为什么是今年?
三大条件成熟:
1. 技术条件具备
- 模型推理能力突破:OpenAI o1、DeepSeek-R1、Gemini 3在复杂推理、长上下文、工具调用上显著提升。
- 工具生态标准化:MCP(模型上下文协议)、A2A(Agent-to-Agent)协议,让智能体能真正接入现实系统。
- 任务执行能力增强:Claude Opus 4.6能完成长达14.5小时的长程任务(50%准确率)。
2. 产业基础建立
- 2025-2026年,全球头部企业建立AI治理、风险管控、AgentOps体系。
- 日本政府推出7家AI平台,2027年计划在18万公务员中实测。
3. 成本大幅下降
- AI推理成本两年内下降超过95%,"每个业务流程部署一个Agent"在经济上可行。
关键数据:
- 支付宝保险模型幻觉率从3%降至0.6%。
- OpenClaw("龙虾")成为开源智能体典型代表。
- 中国大模型周调用量突破7.359万亿Token,连续三周超越美国。
未来趋势:
- 2026-2028年:企业级智能体进入成熟应用期。
- 3-5年后:真正的"Agent原生应用生态"形成,类似2007年iPhone后App经济的爆发节奏。
但专家也提醒:爆发≠成熟。
现在很多"生成式AI"只是改名叫"AI智能体",需要警惕营销炒作。
📌 对你意味着什么:智能体不是概念,是正在发生的产业变革。如果你还没开始规划Agent应用,可能已经落后了。
写在最后
昨天还在争论"谁的参数量大",今天已经是"谁的Token消耗高"、"谁的编程能力强"、"谁的落地更快"。
阿里喊出"国产编程最强",字节晒出120万亿Token消耗,谷歌凌晨开源Gemma 4,国家药监局把AI写进监管体系,新华社定调"智能体爆发年"。
五条线,指向同一个结论:
AI的战场,已经不在"跑分"了。
下一周的看点?智谱GLM-5V-Turbo、字节Seedance 2.0、阿里Qwen3.6-Max都在排队。
好戏还在后面。